|
Researcher at Tencent Hunyuan, working on scaling agents toward general and specialized intelligence. Previously: Sea AI Lab, Microsoft Research. I’m currently based in Singapore. Feel free to reach out : ) Email / Google Scholar / LinkedIn / Github / Twitter |

|
|
|
|
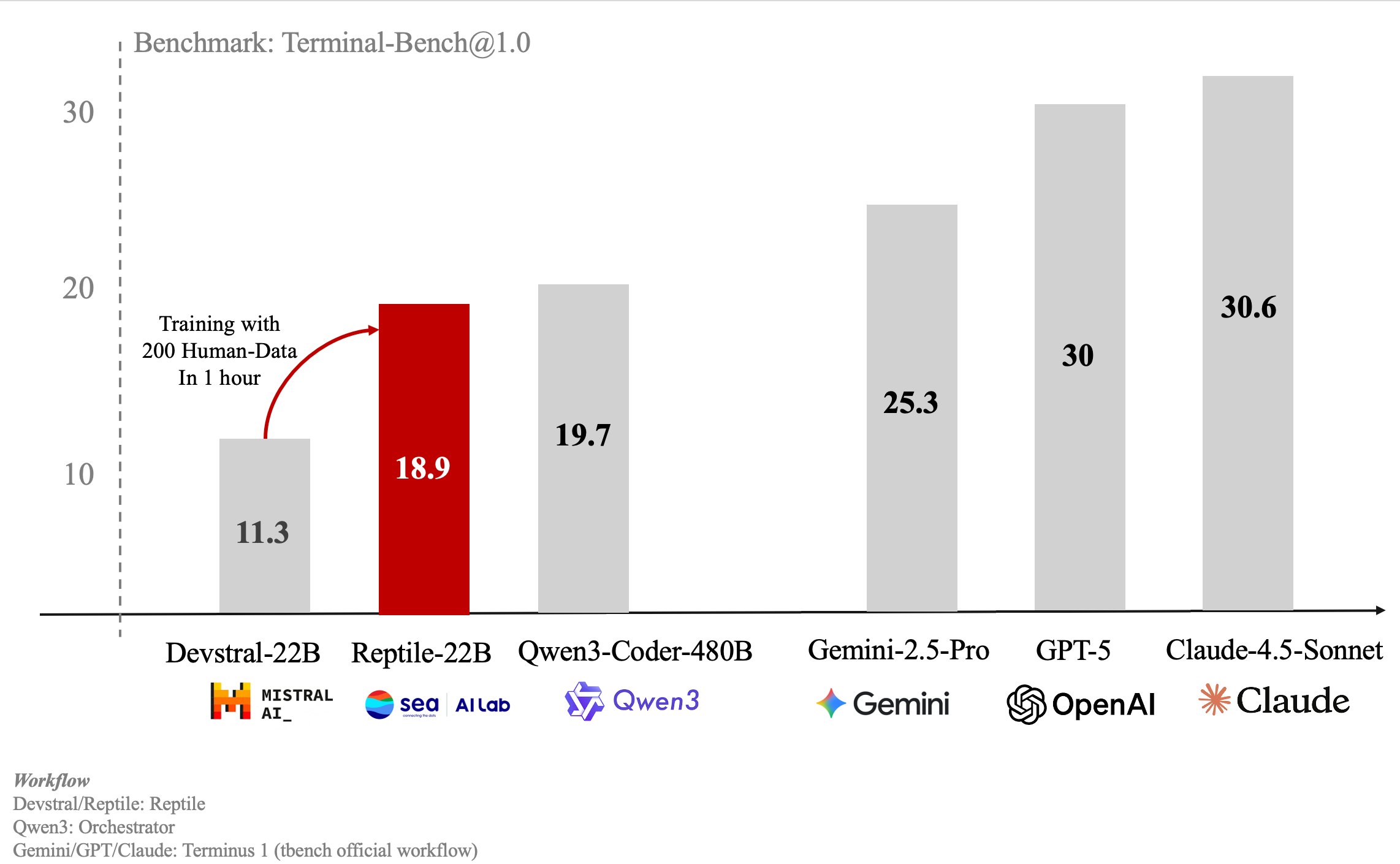
Longxu Dou*, Cunxiao Du*, Shenggui Li*, Tianduo Wang, Tianjie Zhang, Tianyu Liu, Xianwei Chen, Chenxia Tang, Yuanheng Zhao, Min Lin Project, 2025
Compared with other CLI agents (e.g., Claude Code and Mini SWE-Agent), Reptile stands out for the following reasons:
|
|
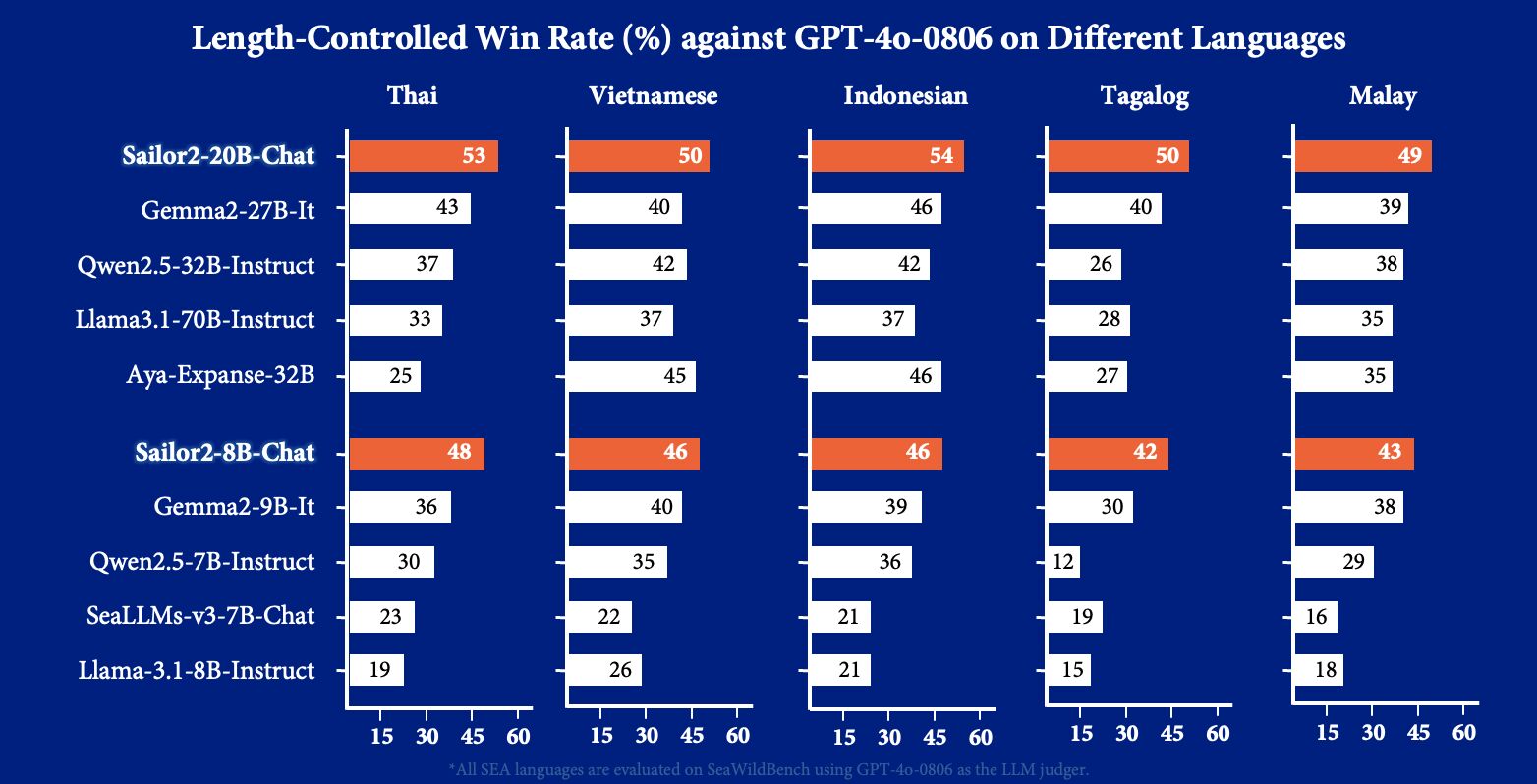
Longxu Dou*, Qian Liu*, Fan Zhou*, Changyu Chen*, Zili Wang, Ziqi Jin, Zichen Liu, Tongyao Zhu, Cunxiao Du, Penghui Yang, Haonan Wang, Jiaheng Liu, Yongchi Zhao, Xiachong Feng, Xin Mao, Man Tsung Yeung, Sailor2 Team Report, 2025 Slides Sailor2 is a community-driven project delivering state-of-the-art multilingual language models in three scales - 1B, 8B, and 20B parameters. Building upon the foundation of Qwen2.5, Sailor2 is continually pre-trained over 500B high-quality tokens to support 15 languages, including English, Chinese, Burmese, Cebuano, Ilocano, Indonesian, Javanese, Khmer, Lao, Malay, Sundanese, Tagalog, Thai, Vietnamese, Waray. |
|
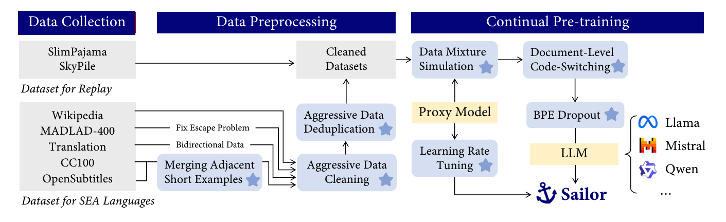
Longxu Dou*, Qian Liu*, Guangtao Zeng, Jia Guo, Jiahui Zhou, Xin Mao, Ziqi Jin, Wei Lu, Min Lin Report, 2024 Slides Sailor is a family of open language models ranging from 0.5B to 14B parameters, tailored for South-East Asian (SEA) languages. These models are continually pre-trained from Qwen1.5, a great language model for multilingual use cases. From Qwen1.5, Sailor models accept 200B to 400B tokens, primarily covering the languages of English, Chinese, Vietnamese, Thai, Indonesian, Malay, and Lao. The training leverages several techniques, including BPE dropout for improving the model robustness, aggressive data cleaning and deduplication, and small proxy models to optimize data mixture. |
|
Design and source code from Jon Barron. |